고정 헤더 영역
상세 컨텐츠
본문
반응형
자~! 이번 시간은 SPSS를 이용한 요인분석을 어떻게 하는지 알려주는 시간이다.
1. 오프닝(오프라인 친구들의 질문 + 답변)
저번 영상에서 상관관계분석을 알려드렸는데, 이 글을 본 오프라인 친구들이 나에게 논문데이터 분석 노하우를 묻는 경우가 생겼다.
질문 1. 분석 순서는 어떻게 되는가?
질문 2. 분석을 할 때 결과 값이 안좋게(예: 상관의 유의성 X, 요인 안 묶임... 등) 나오면 대처 방법은 무엇인가?
답변 : 대부분의 설문데이터 바탕의 졸업논문은 회귀분석, 구조방정식의 경로분석 등 자주 쓰이는 분석들이 정해져 있다. 차차 설명해주기로 하겠다. 물론 데이터 결과가 잘 안 나올 경우에 어떤 실수를 했는지, 어떤 방법으로 하는 것이 옳은지 알려주겠다.
2. 요인분석 개념
요인분석, 말은 학문적으로 그럴듯하게 들린다. 하지만 크게 어려운 개념은 아니다.
** 학문적으로 설명하면 머리 아플테니 ㅋㅋㅋ 쉽게 설명해주겠다.
요인분석 = 즉, 나의 측정 문항들이 어떤 덩어리로, 몇 개의 덩어리로 묶이는지 보는 것.
요인분석에는 2가지가 있다.
- 탐색적 요인분석
- 프로그램 : SPSS 프로그램에서 분석 가능
- 개념 : 연구에 사용되는 측정문항들(여러 변수들의 측정문항이 뒤섞인 상태)을 공분산과 상관관계 분석을 통해 이들을 하나의 요인으로 묶어주는 것이다.
- 사용 목적 : 즉, 내가 가진 측정문항들에서 특정한 요인을 추출하고 싶을 때 사용한다. 보통 선행연구가 별로 없는 연구에서 내가 무언가의 변수를 찾고 싶을 때 사용하며, 핵심적인 몇 개의 변수로 묶어 줌으로 자료의 분석이 더욱 용이해짐. 말 그대로 탐험가처럼 변수를 탐색할 때 쓰인다고 보면 이해하기 쉽다.
- 예: 신용카드가 처음 나왔을 시절에 신용카드 품질에 대한 조사. -> 신용카드 품질을 측정하는 적절한 변수 필요 -> 일단 신용카드와 관련된 품질을 모두 설문함 -> 탐색적 요인분석을 할 경우 "보안성(개인정보와 관련)", "호환성(어느 매장이나 사용가능)", "편리성(현금에 비해 휴대가 용이함)" 등 여러 덩어리가 묶여질 것이다. 이러한 이름은 연구자가 묶여진 측정문항들을 보고 가장 알맞은 단어로 직접 정한다.
- 확인적 요인분석
- 프로그램 : AMOS 프로그램에서 분석 가능
- 개념 : 내가 이미 요인들(=변수들)을 선행연구를 통해 알고 있는 상태에서, 이 요인들 간의 관계가 어떠한지 분석(=파악)하기 위한 것이다.
- 사용목적 : 연구자가 선행연구를 바탕으로 요인에 대한 정보을 알고 있을 때 사용한다. 즉, 내가 이러한 변수들(=요인들)을 알고 있고, 이 변수들 간의 관계를 파악하고 싶을 때 사용한다. 쉽게 말해, 선행연구를 참고하여 만든 내 설문 문항들이 선행연구처럼 각각 변수들(=요인들)로 잘 나눠지는지 확인하고 싶을 때 사용한다고 생각하면 이해하기 쉽다.
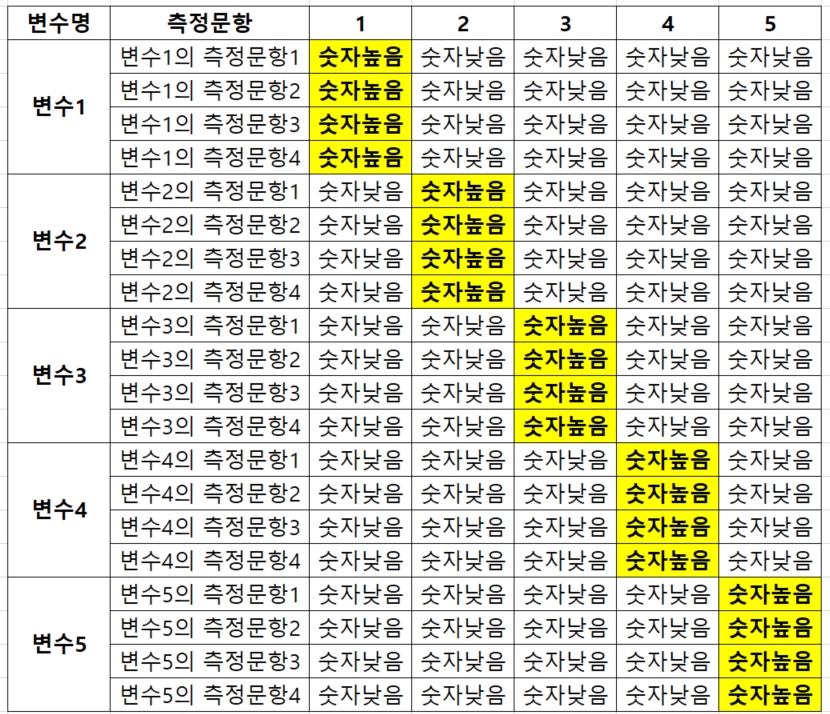
아래의 그램은 SPSS로 분석한 탐색적 요인분석 결과를 아~~주 보기 쉽게 나타낸 표이다.
우리가 원하는 모습은 바로 이 모습이다. 많은 친구들이 이 모습이 안나와서 좌.절.하.며, 분.노.하.고, 슬.퍼.한.다.
<SPSS 탐색적 요인분석 결과 예시>
<SPSS 탐색적 요인분석의 나쁜 예시> (이러면 망한 것이다)

3. 탐색적 요인분석 방법
1) 분석 -> 차원축소 -> 요인분석 클릭
이전 포스팅(상관관계분석)에서 측정문항을 변수로 뭉치는 방법(=평균 구하기를 통해 1개의 변수로 바꿈 / 엑셀에서 계산 추천, 이유: 난 엑셀이 더 편해서... ㅋㅋㅋ)을 통해 연구에서 사용되는 변수들을 다 구해준다.

2) 독립변수, 매개변수, 종속변수 구분할 것 없이 일단 다~~ 옮긴다.
이유 : 상식적으로 엄격하게 생각해보자! 사실 데이터에는 독립, 매개, 종속이런 개념이 없고 단순히 5,4,4,4,4,4, 이런 숫자들만 존재한다. 이런 상황에서, 우리가 의도했던 독립, 매개, 종속이 한꺼번에 넣고 돌렸을 때 구별이 안된다면? 우리의 데이터를 믿을 수 있겠는가?
여러분이 논문 심사자라면 어?? 왜 측정문항들이 변수별로 구별이 안되지? 왜 섞이지? 질문 잘못한거 아냐? 제대로 했어?라고 생각하지 않을까? -> 맞다. 다~~ 넣고 돌렸을 때 독립, 종속, 매개로 탁탁탁 나눠져야만 우리는 이 데이터가 제대로 조사되었구나라고 생각할 것이다. 그러니 제~~발 제대로 설문지를 배부하고 수거하자! (설문 당시 귀찮다고 친구에게 30부씩 받아달라고 맡기거나, 내 설문지를 사람들에게 제대로 설명 못한 상황에서 설문을 진행하면 요인분석할 때 매우 슬픈 상황이 발생한다.ㅠㅠ)
독립변수, 매개변수, 종속변수 구분 없이 다 옮기자~!


3) 탐색적 요인분석의 옵션 설정-> 계수, KMO와 Bartlett 구형성 검정 클릭
여러 옵션이 있지만, 계수, KMO와 Bartlett의 구형성 검정을 채크한다.
이것만 봐도 충분히 논문을 쓸 수 있기 때문에 이유는 크게 묻지 말자. 일단 외우자!
- KMO 값 의미 : 요인들(=변수들) 간에 상관관계가 어느 정도인가를 나타내는 지표이다.
- KMO 값 기준 : 0.5 이상(사회과학 분야에 따라 0.8 이상을 원하는 분야도 있음)
- Bartlett 구형성 검정 의미 : 변수들 간에 연관성이 있으므로 탐색적 요인분석을 실시해도 좋은지 판단하는 기준이 되는 지표
- Bartlett 구형성 검정 기준 : 유의확률이 0.05 이하로 나타나야 한다. 즉, 유의한 것으로 나타나야 한다.

4) 요인회전 선택 -> 베리멕스 선택 -> 계속 선택
베리멕스는 좀 더 엄밀히 말하자면 직각 베리멕스 회전이다. 많은 옵션 중에서 베리멕스를 선택하는 이유는 요인들(=변수들) 간에 독립성을 유지하면서 회전시키는 방법이다. 여러분이 이보다 더 자세하게 알기를 원하면 머리가 아플 것 같아서 다음 실습으로 넘어가겠다.

5) 옵션 선택 -> 작은 계수 표시 안 함 클릭 -> 계속
일단 우리는 우리의 데이터가 좋은지 나쁜지 봐야하므로 "작은 계수 표지 안 함", "0.5"를 설정하여 분석의 가독성을 향상시키자!!!

6) 다시 요인분석 화면에서 "확인" 클릭
측정문항을 옮겼고, 기술통계, 요인회전, 옵션을 모두 설정하였다면, "확인"을 눌러주자!!

7) 해석
본 포스팅의 예시에서는 KMO 값이 기준치인 0.8이상으로 나탔으며, 요인들 간 상관성이 있다는 것을 확인하였다. Bartlett의 구형성 검정 결과에서도 유의확률이 0.000으로 나타나 탐색적 요인분석을 하기에 적절한 것으로 나타났다.
이에 대한 기준을 다시 적어주겠다.
KMO 값 기준 : 0.5 이상(사회과학 분야에 따라 0.8 이상도 있음)
Bartlett 구형성 검정 기준 : 유의확률 < 0.05

공통성 분석 결과 0.5 이상으로 나타나 요인(=변수)의 분산이 측정문항들에 의해 설명이 50%이상 되는 것으로 나타났다.
공통성 기준 : 0.5 이상

누적된 설명 총분산은 72.852%로 나타났고 본 포스팅에서 사용된 데이터는 총 7개의 요인으로 묶여졌다.

요인분석의 결과는 가독성을 위해 0.5 이하의 값은 안보이게 설정하였다.
*** 원래는 모든 데이터가 다 보여야한다.!!!!! 진짜로!!! 일단 예제 실습이니까 보기 좋게 안 보이게 한 것이다.
변수 1, 2, 3, 4, 5, 6, 7 로 묶였으며, 원래 의도했던 대로 변수들이 잘 묶인 것을 확인 할 수 있다.
이 데이터는 예제로 쓸만큼 잘 수거된 설문 데이터이다.
(실제 게재에 쓰이는 도중의 데이터이다. 익명을 유지하기 위해 변수를 X로 처리하였다.)
여러분이 처음 설문을 하고 코딩을 한 뒤, 요인분석을 해보면 분노, 슬픔이 여러분과 함께 할 것이다.
요인이 생각대로 안 묶일 경우 대처 방안
- 회전된 성분행렬 표에서 숫자가 유독 낮거나, 숫자가 안보이는 측정문항을 제거한 뒤, 다시 요인분석을 해보아라
- 설문지의 측정문항이 애초에 잘못된 것은 아닌지 확인하라
- 다시 설문하라... 이 방법이 FM, 정석이다. (그러니 제~~발 설문할 때 제대로 하자!)

오늘은 요인분석 중에서 SPSS로 분석이 가능한 탐색적 요인분석에 대해 살펴보았다.
여러분들이 넘어야 하는 산 중에서 가장 먼저 넘어야하는 큰 산이다.
뒤에 다중공선성, 회귀분석(단순, 다중)의 경로계수 유의수준, 설명력 등 넘어야하는 산이 많다.
힘 내시고!!! 통계친구가 있으니 걱정하지 말자!!! 할 수 있다!!!
다음 포스팅은 신뢰성과 타당성이 무엇이고 지금 까지 배운 신뢰도 구하기, 탐색적 요인분석과 어떤 관련이 있는지 설명하도록 하겠다.
안녕~!!!
반응형





댓글 영역